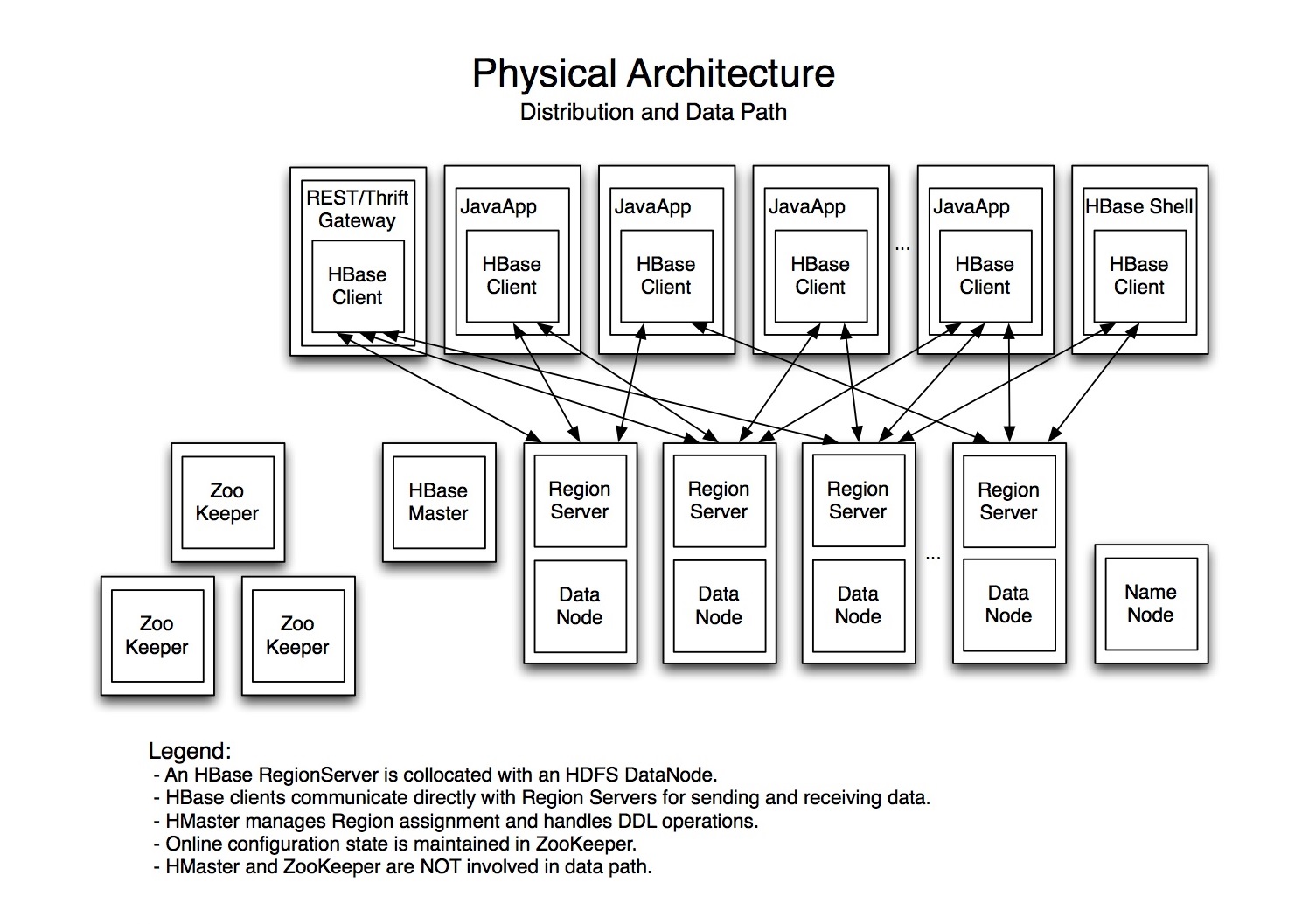
1) Connect to HBase. Connect to your running instance of HBase using the hbase shell command, located in the bin/ directory of your HBase install.
$ ./bin/hbase shell
hbase(main):001:0>
2) Create a table. Use the create command to create a new table. You must specify the table name and the ColumnFamily name.
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
3) List Information About your Table.
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
4) Put data into your table. Here, we insert three values, one at a time. The first insert is at row1, column cf:a, with a value of value1. Columns in HBase are comprised of a column family prefix, cf in this example, followed by a colon and then a column qualifier suffix, a in this case.
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
5) Scan the table for all data at once. One of the ways to get data from HBase is to scan. Use the scan command to scan the table for data. You can limit your scan, but for now, all data is fetched.
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
6) Get a single row of data.
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
7) Disable a table. If you want to delete a table or change its settings, as well as in some other situations, you need to disable the table first, using the disable command. You can re-enable it using the enable command.
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
8) Disable the table again if you tested the enable command above:
hbase(main):010:0> disable 'test'
0 row(s) in 1.1820 seconds
9) Drop the table.
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
10) Backup and restore to S3:
10.1) BackUp:
hadoop jar /home/hadoop/lib/hbase.jar emr.hbase.backup.Main --backup --backup-dir s3://your-bucket/backups/j-XXXX
10.2) Restore:
hadoop jar /home/hadoop/lib/hbase.jar emr.hbase.backup.Main --restore --backup-dir s3://your-bucket/backup-hbase/j-XXXX'
10.3) Import:
hbase org.apache.hadoop.hbase.mapreduce.Import test s3n://your-bucket/backup-hbase/j-XXXX
11) Backup and Restore with Distcp and S3distCp:
11.1) Using Distcp method to backup to S3:
hadoop distcp hdfs://ec2-52-16-22-167.eu-west-1.compute.amazonaws.com:9000/hbase/ s3://your-bucket/hbase/201502280715/
11.2) Using Distcp to backup to another cluster:
hadoop distcp hdfs://ec2-52-16-22-167.eu-west-1.compute.amazonaws.com:9000/hbase/ hdfs://ec2-54-86-229-249.compute-1.amazonaws.comec2-2:9000/hbase/
11.3) Using S3distcp method to backup to S3:
hadoop jar ~/lib/emr-s3distcp-1.0.jar --src hdfs:///hbase/ --dest s3://your-bucket/hbase/201502280747/