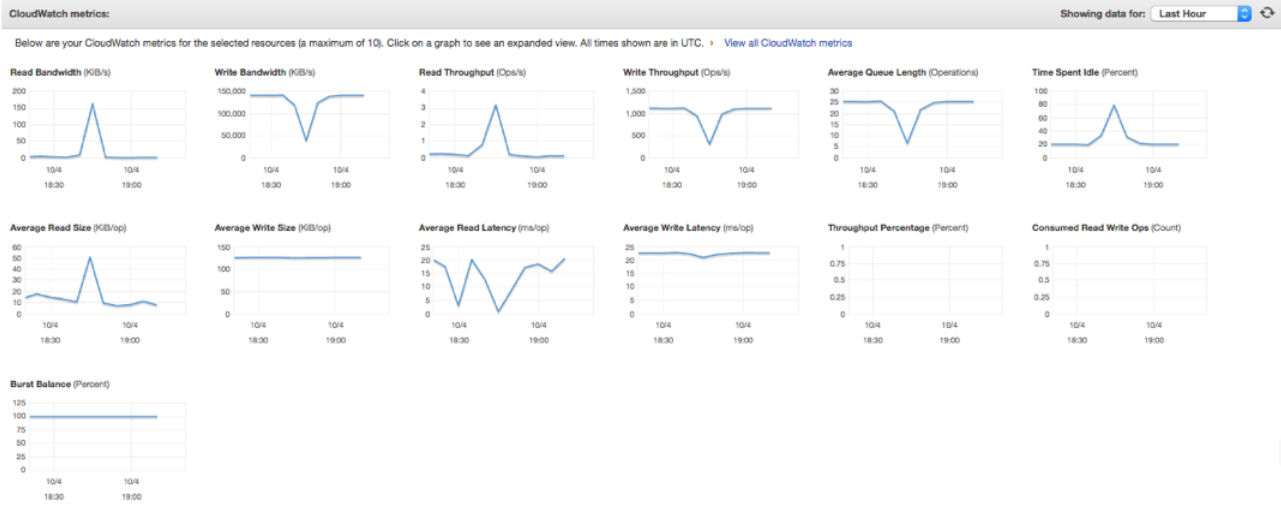
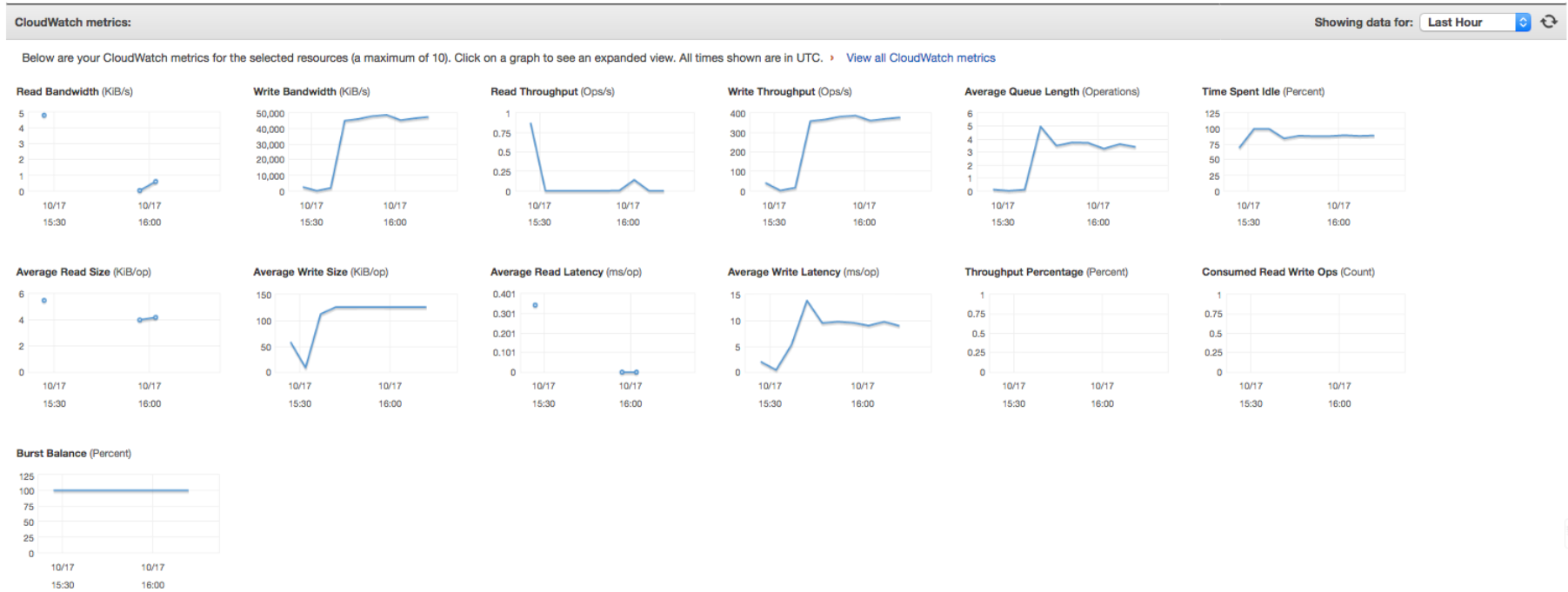
Before proceeding:
This procedure considers that you don’t have any current useful data on HDFS. All the data will be lost after adding mount points with this method.
This procedure should be applied to every datanode in the cluster. No intervention in the master node is needed if the framework is configured properly.
#checking available block devices:
[ec2-user@ip-10-0-15-76 media]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme2n1 259:4 0 2.5T 0 disk
nvme1n1 259:3 0 2.5T 0 disk /media/ebs0
nvme4n1 259:6 0 2.5T 0 disk
nvme0n1 259:0 0 2G 0 disk
├─nvme0n1p1 259:1 0 2G 0 part /
└─nvme0n1p128 259:2 0 1M 0 part
nvme3n1 259:5 0 2.5T 0 disk
#checking formatted filesystem:
[ec2-user@ip-10-0-15-76 media]$ sudo file -s /dev/nvme2n1
/dev/nvme2n1: data
(this filesystem is not formatted)
#formatting to ext4:
[ec2-user@ip-10-0-15-76 media]$ sudo mkfs -t ext4 /dev/nvme2n1
mke2fs 1.42.12 (29-Aug-2014)
Creating filesystem with 655360000 4k blocks and 163840000 inodes
Filesystem UUID: 6d9c997f-d47b-4529-85c8-e56e8ef47a1d
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848, 512000000, 550731776, 644972544
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
#mounting
[ec2-user@ip-10-0-15-76 media]$ sudo mkdir /media/ebs1
[ec2-user@ip-10-0-15-76 media]$ sudo mount /dev/nvme2n1 /media/ebs1
[ec2-user@ip-10-0-15-76 media]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme2n1 259:4 0 2.5T 0 disk /media/ebs1
nvme1n1 259:3 0 2.5T 0 disk /media/ebs0
nvme4n1 259:6 0 2.5T 0 disk
nvme0n1 259:0 0 2G 0 disk
├─nvme0n1p1 259:1 0 2G 0 part /
└─nvme0n1p128 259:2 0 1M 0 part
nvme3n1 259:5 0 2.5T 0 disk
#final mount result
[ec2-user@ip-10-0-60-46 ~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme2n1 259:4 0 2.5T 0 disk /media/ebs1
nvme1n1 259:3 0 2.5T 0 disk /media/ebs0
nvme4n1 259:6 0 2.5T 0 disk /media/ebs3
nvme0n1 259:0 0 2G 0 disk
├─nvme0n1p1 259:1 0 2G 0 part /
└─nvme0n1p128 259:2 0 1M 0 part
nvme3n1 259:5 0 2.5T 0 disk /media/ebs2
#checking mount points in hdfs-site.xml
[ec2-user@ip-10-0-60-46 media]$ cat /opt/hadoop-2.7.3/etc/hadoop/hdfs-site.xml |grep -A1 dfs.datanode.data.dir
<name>dfs.datanode.data.dir</name>
<value>/media/ebs0/hadoop/datanodes,/media/ebs1/hadoop/datanodes,/media/ebs2/hadoop/datanodes,/media/ebs3/hadoop/datanodes</value>
# create defined directory structure on mount point (for each mount point):
sudo mkdir -p /media/ebs1/hadoop/datanodes
# modify owner to the user that will start DFS (for each mount point):
sudo chown -R ec2-user:ec2-user /media/ebs1/hadoop/datanodes
#format namenode:
hadoop namenode -format
# stop/start DFS:
/opt/hadoop-2.7.3/sbin/stop-dfs.sh
/opt/hadoop-2.7.3/sbin/start-dfs.sh
# check service start status
tail -f /var/log/hadoop/hadoop-ec2-user-datanode-ip-10-0-15-76.log
**some ENV variables I usually use on these environments:
export HADOOP_SSH_OPTS="-i /home/ec2-user/.ssh/mykey -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null"
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.151.x86_64/jre