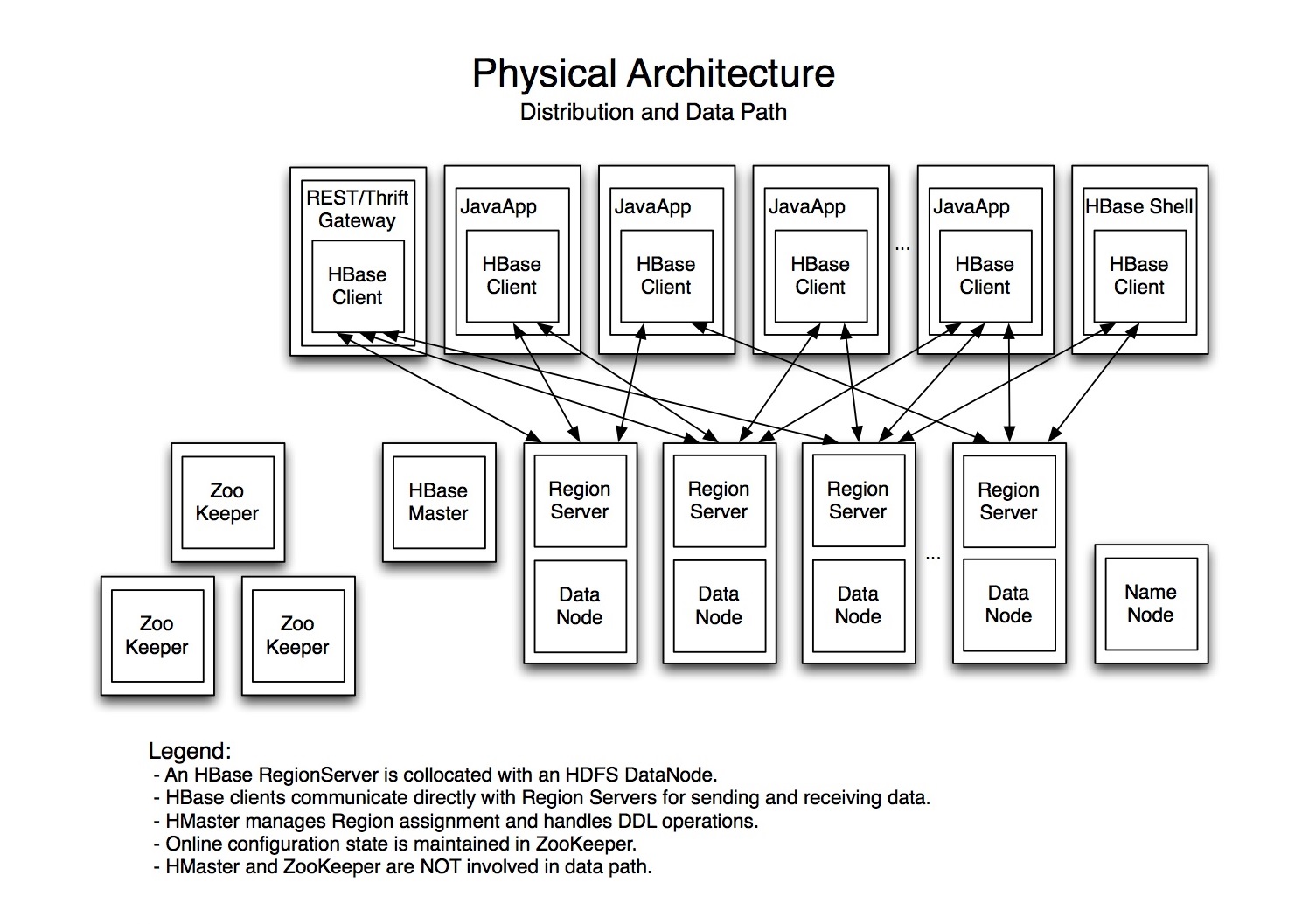
There are a lot of articles about this, but, I just needed a good summary of concepts:
Hadoop 1:
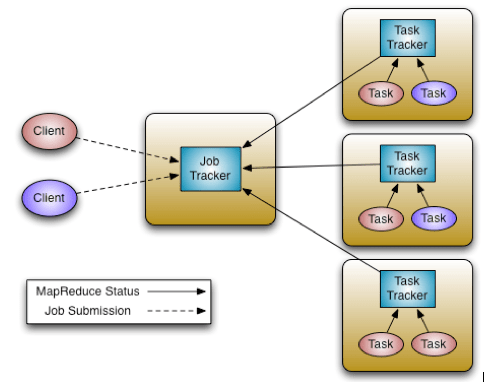 A master process called the JobTracker is the central scheduler for all MapReduce jobs in the cluster.
A master process called the JobTracker is the central scheduler for all MapReduce jobs in the cluster.
Nodes have a TaskTracker process that manages tasks on the individual nodes. The TaskTrackers, communicate with and are controlled by the JobTracker. Similar to most resource managers, the JobTracker has two pluggable scheduler modules, Capacity and Fair.
The JobTracker is responsible for managing the TaskTrackers on worker server nodes, tracking resource consumption and availability, scheduling individual job tasks, tracking progress, and providing fault tolerance for tasks.
The TaskTracker is directed by the JobTracker and is responsible for launch and tear down of jobs and provides task status information to the JobTracker.
The TaskTrackers also communicate through heartbeats to the JobTracker: If the JobTracker does not receive a heartbeat from a TaskTracker, it assumes it has failed and takes appropriate action (e.g., restarts jobs).
Hadoop 2 (YARN):

In YARN, the job tracker is split into two different daemons called ResourceManager and NodeManager (node specific).
Also there are new components: an ApplicationMaster and application Containers.
The ResourceManager is a pure scheduler. Its sole purpose is to manage available resources among multiple applications on the cluster. As with version 1, both Fair and Capacity scheduling options are available.
The ApplicationMaster is responsible for accepting job submissions, negotiating resource Containers from the ResourceManager, and tracking progress.
ApplicationMasters are specific to and written for each type of application. For example, YARN includes a distributed Shell framework that runs a shell script on multiple nodes on the cluster. The ApplicationMaster also provides the service for restarting the ApplicationMaster Container on failure.
ApplicationMasters request and manage Containers, which grant rights to an application to use a specific amount of resources (memory, CPU, etc.) on a specific host.
The ApplicationMaster, once given resources by the ResourceManager, contacts the NodeManager to start individual tasks. For example, using the MapReduce framework, these tasks would be mapper and reducer processes.
The NodeManager is the per-machine framework agent that is responsible for Containers, monitoring their resource usage (CPU, memory, disk, network), and reporting back to the ResourceManager.
On previous figure we have two ApplicationMasters running within the cluster, one of which has three Containers (the red client) and one that has one Container (the blue client). Note that the ApplicationMasters run on cluster nodes and not as part of the ResourceManager, thus reducing the pressure on a central scheduler. Also, because ApplicationMasters have dynamic control of Containers, cluster utilization can be improved.
Facts:
– Hadoop 2 has the concept of containers, while Hadoop 1 has slots. Containers are generic and can run any type of tasks, but a slot can run either a map or a reduce task.
– The same MR program without any modifications can be executed in Hadoop 1 and 2, but needs to be compiled with the appropriate set of jar files.
– Hadoop 1 allows us to write programs in only MR, while Hadoop 2 with resource management framework (YARN) allows to write programs in multiple distributed computing models. As example MR, Spark, Hama, Giraph, MPI and HBase coprocessors, among others.