The challenge that architects and developers face today is how to process large volumes of data in a timely, cost effective, and reliable manner. There are several NoSQL solutions in the market today, and choosing the right one for your use case can be difficult.
Both Amazon DynamoDB and Apache HBase are available in the Amazon Web Services (AWS) cloud.
DynamoDB Overview:
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Amazon DynamoDB offers the following benefits:
– No administrative overhead—Amazon DynamoDB manages the burdens of hardware provisioning, setup and configuration, replication, cluster scaling, hardware and software updates, and monitoring and handling of hardware failures.
– Virtually unlimited throughput and scale—The provisioned throughput model of Amazon DynamoDB allows you to specify throughput capacity to serve nearly any level of request traffic. With Amazon DynamoDB, there is virtually no limit to the amount of data that can be stored and retrieved.
– Elasticity and flexibility: —Amazon DynamoDB can handle unpredictable workloads with predictable performance and still maintain a stable latency profile that shows no latency increase or throughput decrease as the data volume rises with increased
– Integration with other AWS services: DynamoDB integrates seamlessly with other AWS services such as Amazon Identity and Access Management (Amazon IAM) to control access to DynamoDB resources, CloudWatch to monitor a variety of DynamoDB performance metrics, Amazon Kinesis for real-time data ingestion, S3 Storage Service for Internet storage, Amazon EMR to provide enhanced advanced analytics capabilities, Amazon Redshift to provide business intelligence capabilities, and AWS Data Pipeline to automate data-driven workflows.
Apache HBase Overview:
Apache HBase, a Hadoop database, offers the following benefits:
– Efficient storage of sparse data—Apache HBase provides fault-tolerant storage for large quantities of sparse data using column-based compression. Apache HBase is capable of storing and processing billions of rows and millions of columns per row.
– Store for high frequency counters—Apache HBase is suitable for tasks such as high-speed counter aggregation because of its consistent reads and writes.
– High write throughput and update rates—Apache HBase supports low latency lookups and range scans, efficient updates and deletions of individual records, and high write throughput.
– Support for multiple Hadoop jobs—The Apache HBase data store allows data to be used by one or more Hadoop jobs on a single cluster or across multiple Hadoop clusters.
Hbase vs DynamoDB Throughput Model:
DynamoDB uses a provisioned throughput model to process data. During table creation time, it automatically partitions and reserves the appropriate amount of resources to meet your specified throughput requirements.
To decide on the required read and write throughput values for a table, consider the following factors:
– Item size: The read and write capacity units that you specify are based on a predefined data item size per read or per write operation.
– Expected read and write request rates: You must also determine the expected number of read and write operations your application will perform against the table, per second.
– Consistency: Whether your application requires strongly consistent or eventually consistent reads is a factor in determining how many read capacity units you need to provision for your table.
– Local secondary indexes: Queries against indexes consume provisioned read throughput.
– Global secondary indexes: The provisioned throughput settings of a global secondary index are separate from those of its parent table. Therefore, the expected workload on the global secondary index also needs to be taken into consideration when specifying the read and write capacity at index creation time.
Although read and write requirements are specified at table creation time, DynamoDB lets you increase or decrease the provisioned throughput to accommodate load with no downtime.
In HBase, the number of nodes in a cluster can be driven by the required throughput for reads and/or writes. The available throughput on a given node can vary depending on the data, specifically:
– Key/value sizes
– Data access patterns
– Cache hit rates
– Node and system configuration
You should plan for peak load if load will likely be the primary factor that increases node count within a HBase cluster.
Hbase vs DynamoDB Consistency Model:
Eventual consistency option is the default in DynamoDB and maximizes the read throughput. But, it lets you specify the desired consistency for each read request within an application. You can specify whether a read is eventually consistent or strongly consistent.
Please note: An eventually consistent read might not always reflect the results of a recently completed write. Consistency across all copies of data is usually reached within a second.
A strongly consistent read in DynamoDB returns a result that reflects all writes that received a successful response prior to the read.
HBase reads and writes are strongly consistent. This means that all reads and writes to a single row in Apache HBase are atomic. Each concurrent reader and writer can make safe assumptions about the state of a row. Multi-versioning and time stamping in Apache HBase contribute to its strongly consistent model.
Hbase vs DynamoDB Table Operations:
In summary, DynamoDB and HBase have similar data processing models in that they both support only atomic single-row transactions. Both databases also provide batch operations for bulk data processing across multiple rows and tables.
One key difference between the two databases is the flexible provisioned throughput model of Amazon DynamoDB. The ability to dial up capacity when you need it and dial it back down when you are done is useful for processing variable workloads with unpredictable peaks.
For workloads that need high update rates to perform data aggregations or maintain counters, Apache HBase is a good choice. This is because Apache HBase supports a multi-version concurrency control mechanism, which contributes to its strongly consistent reads and writes. Amazon DynamoDB gives you the flexibility to specify whether you want your read request to be eventually consistent or strongly consistent depending on your specific workload.
Hbase vs DynamoDB Partitioning:
DynamoDB stores three geographically distributed replicas of each table to enable high availability and data durability within a region.
Data is auto-partitioned primarily using the hash key: as throughput and data size increase, it will automatically repartition and reallocate data across more nodes.
Partitions in DynamoDB are fully independent, resulting in a shared nothing cluster. However, provisioned throughput is divided evenly across the partitions.
A region is the basic unit of scalability and load balancing in HBase. Region splitting and subsequent load-balancing follow this sequence of events:
1. Initially there is only one region for a table, and as more data is added to it, the system monitors the load to ensure that the configured maximum size is not exceeded.
2. If the region size exceeds the configured limit, the system dynamically splits the region into two at the row key in the middle of the region, creating two roughly equal halves.
3. The master then schedules the new regions to be moved off to other servers for load balancing, if required.
Behind the scenes, Zookeeper tracks all activities that take place during a region split and maintains the state of the region in case of server failure.
HBase regions are equivalent to range partitions that are used in RDBMS sharding. Regions can be spread across many physical servers that consequently distribute the load, resulting in scalability.
HBase Performance and Modeling Notes:
In HBase, the most basic unit is a column. One or more columns form a row. Each row is addressed uniquely by a primary key referred to as a row key. A row in HBase can have millions of columns. Each column can have multiple versions with each distinct value contained in a separate cell.
One fundamental modeling concept in Apache HBase is that of a column family. A column family is a container for grouping sets of related data together within one table.
HBase groups columns with the same general access patterns and size characteristics into column families to form a basic unit of separation.
Column families allow you to fetch only those columns that are required by a query. All members of a column family are physically stored together on a disk. This means that optimization features, such as performance tunings, compression encodings, and so on, can be scoped at the column-family level.
For performance reasons, it is important to keep the number of column families in your Apache HBase schema low. Anything above three-column families can potentially degrade performance. The recommended best practice is to maintain a one-column family in your schemas and introduce a second-column family and third-column family only if data access is limited to a one-column family at a time.
Note that Apache HBase does not impose any restrictions on row size.
HBase Memory:
Memory is the most restrictive element in Apache HBase. Performance-tuning techniques are focused on optimizing memory consumption.
From a schema design perspective, it is important to bear in mind that every cell stores its value as fully qualified with its full row key, column family, column name, and timestamp on disk. If row and column names are long, the cell value coordinates might become very large and take up more of Apache HBase allotted memory. This can cause severe performance implications, especially if the dataset is large.
HBase Configurations:
HBase supports built-in mechanisms to handle region splits and compactions. Split/compaction storms can occur when multiple regions grow at roughly the same rate, and eventually split at about the same time. This can cause a large spike in disk I/O because of the compactions needed to rewrite the split regions.
Rather than relying on Apache HBase to automatically split and compact the growing regions, you can perform these tasks manually. You can perform them in a time-controlled manner and stagger them across all regions to spread the I/O load as much as possible to avoid potential split/compaction storms. With the manual option, you can further alleviate any problematic split/compaction storms and gain additional performance.
Schema Design:
A region can run hot when dealing with a write pattern that does not distribute load across all servers evenly. This is a common scenario when dealing with streams processing events with time series data. The gradually increasing nature of time series data can cause all incoming data to be written to the same region.
This concentrated write activity on a single server can slow down the overall performance of the cluster. This is because inserting data is now bound to the performance of a single machine. This problem is easily overcome by employing key design strategies such as the following:
– Applying salting prefixes to keys; in other words, prepending a random number to a row.
– Randomizing the key with a hash function.
– Promoting another field to prefix the row key.
These techniques can achieve a more evenly distributed load across all servers.
Client API Considerations:
There are a number of optimizations to take into consideration when reading or writing data from a client using the Apache HBase API. For example, when performing a large number of PUT operations, you can disable the auto-flush feature. Otherwise, the PUT operations will be sent one at a time to the region server.
Whenever you use a scan operation to process large numbers of rows, use filters to limit the scan scope. Using filters can potentially improve performance. This is because column over-selection can incur a nontrivial performance penalty, especially over large data sets.
As a recommended best practice, set the scanner-caching to a value greater than the default of 1, especially if Apache HBase serves as an input source for a MapReduce job.
Setting the scanner-caching value to 500, for example, will transfer 500 rows at a time to the client to be processed, but this might potentially cost more in memory consumption.
Compression Techniques:
Data compression is an important consideration in Apache HBase production workloads. Apache HBase natively supports a number of compression algorithms that you can enable at the column family level.
Enabling compression yields better performance.
In general, compute resources for performing compression and decompression tasks are typically less than the overheard for reading more data from disk.
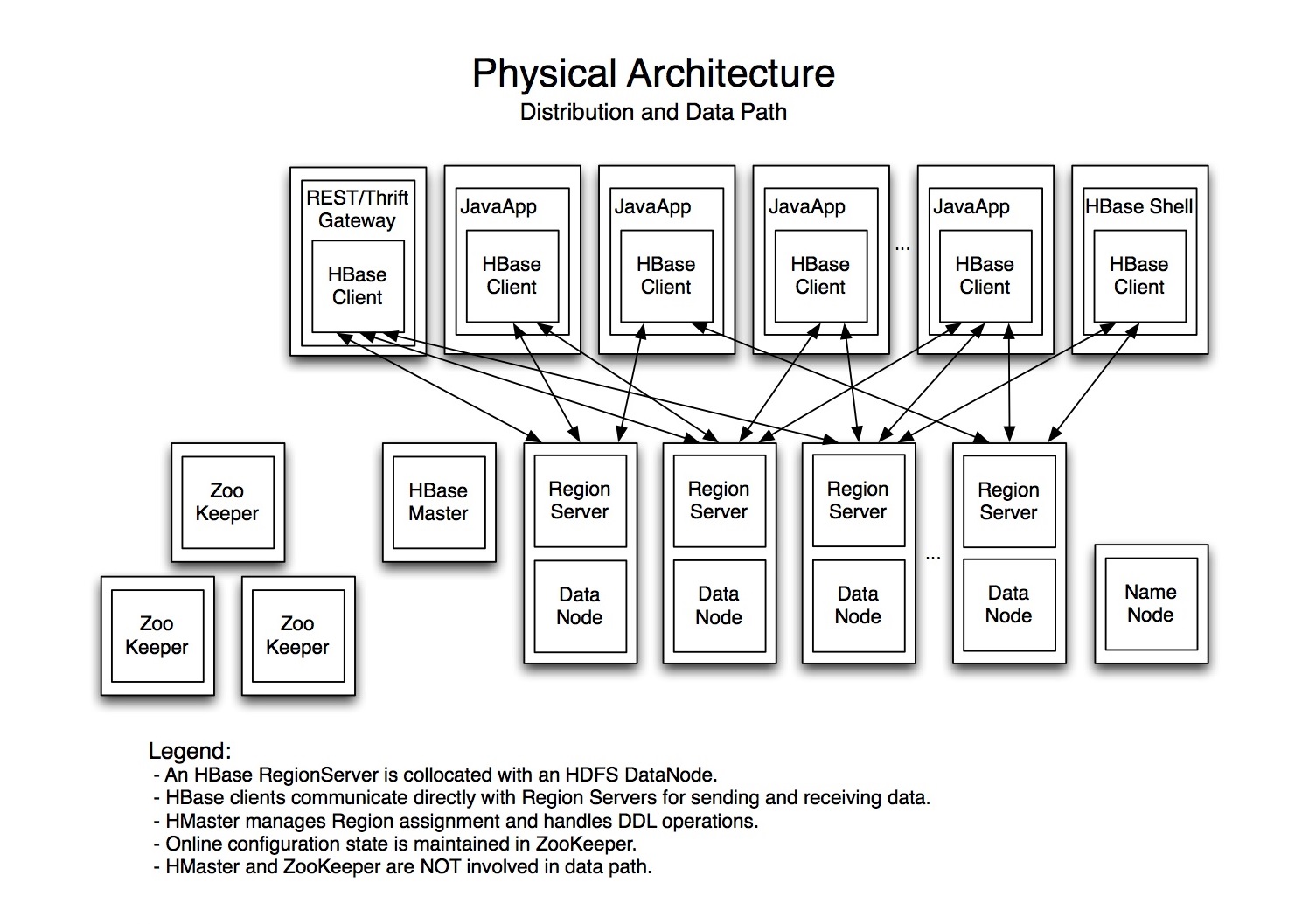
Apache HBase Architecture:
HBase is typically deployed on top of the Hadoop Distributed File System (HDFS), which provides a scalable, persistent, storage layer.
Apache ZooKeeper is a critical component for maintaining configuration information and managing the entire Apache HBase cluster.
The three major Apache HBase components are the following:
– Client API
– Master server
– Region servers
HBase stores data in indexed store files called HFiles on HDFS. The store files are sequences of blocks with a block index stored at the end for fast lookups.
The store files provide an API to access specific values as well as to scan ranges of values, given a start and end key.
During a write operation, data is first written to a commit log called a write-ahead-log (WAL) and then moved into memory in a structure called Memstore.
When the size of the Memstore exceeds a given maximum value, it is flushed as an HFile to disk. Each time data is flushed from Memstores to disk, new HFiles must be created. As the number of HFiles builds up, a compaction process merges the files into fewer, larger files.
A read operation essentially is a merge of data stored in the Memstores and in the HFiles.
The WAL is never used in the read operation. It is meant only for recovery purposes if a server crashes before writing the in-memory data to disk.
A region in Apache HBase acts as a store per column family. Each region contains contiguous ranges of rows stored together.
Regions can be merged to reduce the number of store files. A large store file that exceeds the configured maximum store file size can trigger a region split.
A region server can serve multiple regions. Each region is mapped to exactly one region server. Region servers handle reads and writes, as well as keep data in-memory until enough is collected to warrant a flush.
Clients communicate directly with region servers to handle all data-related operations.
The master server is responsible for monitoring and assigning regions to region servers and uses Apache ZooKeeper to facilitate this task.
Apache ZooKeeper also serves as a registry for region servers and a bootstrap location for region discovery.
The master server is also responsible for handling critical functions such as load balancing of regions across region servers, region server failover, and completing region splits, but it is not part of the actual data storage or retrieval path.
Source:
Click to access AWS_Comparing_the_Use_of_DynamoDB_and_HBase_for_NoSQL.pdf