
Apache Spark, is an open source cluster computing framework originally developed at University of California, Berkeley but was later donated to the Apache Software Foundation where it remains today. In contrast to Hadoop’s two-stage disk-based MapReduce paradigm, Spark’s multi-stage in-memory primitives provides performance up to 100 faster for certain applications.
RDD’s:
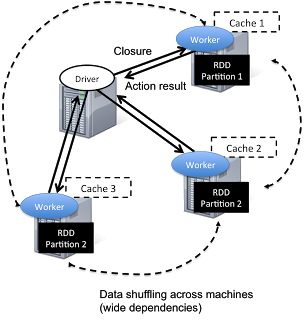
Spark has a driver program where the application logic execution is started, with multiple workers which processing data in parallel.
The data is typically collocated with the worker and partitioned across the same set of machines within the cluster. During the execution, the driver program will pass the code/closure into the worker machine where processing of corresponding partition of data will be conducted.
The data will undergoing different steps of transformation while staying in the same partition as much as possible (to avoid data shuffling across machines). At the end of the execution, actions will be executed at the worker and result will be returned to the driver program.
Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel.

There are currently two types of RDDs:
- parallelized collections, which take an existing Scala collection and run functions on it in parallel.
- Hadoop datasets, which run functions on each record of a file in Hadoop distributed file system or any other storage system supported by Hadoop.
Both types of RDDs can be operated on through the same methods. Each application has a driver process which coordinates its execution.
Running Applications:
Spark applications are similar to MapReduce “jobs”. Each application is a self-contained computation which runs some user-supplied code to compute a result. As with MapReduce jobs, Spark applications can make use of the resources of multiple nodes.
This process can run in the foreground (client mode) or in the background (cluster mode). Client mode is a little simpler, but cluster mode allows you to easily log out after starting a Spark application without terminating the application.
Spark starts executors to perform computations. There may be many executors, distributed across the cluster, depending on the size of the job. After loading some of the executors, Spark attempts to match tasks to executors.
Spark can run in two modes:
- Standalone mode: Spark uses a Master daemon which coordinates the efforts of the Workers, which run the executors. Standalone mode is the default, but it cannot be used on secure clusters.
- YARN mode: The YARN ResourceManager performs the functions of the Spark Master. The functions of the Workers are performed by the YARN NodeManager daemons, which run the executors. YARN mode is slightly more complex to set up, but it supports security, and provides better integration with YARN’s cluster-wide resource management policies.
Spark Execution Parameters
–num-executors: The –num-executors command-line flag or spark.executor.instances configuration property control the number of executors requested
–executor-cores: This property controls the number of concurrent tasks an executor can run. –executor-cores 5 means that each executor can run a maximum of five tasks at the same time.
Every Spark executor in an application has the same fixed number of cores and same fixed heap size.
The number of cores can be specified with the –executor-cores flag when invoking spark-submit, spark-shell, and pyspark from the command line.
The heap size can be controlled with the –executor-cores flag or the spark.executor.memory property.
–executor-memory: This property controls the executor heap size, but JVMs can also use some memory off heap, for example for interned Strings and direct byte buffers.
The value of the spark.yarn.executor.memoryOverhead property is added to the executor memory to determine the full memory request to YARN for each executor.
It defaults to max(384, .07 * spark.executor.memory).
Application Master:
Is a non-executor container with the special capability of requesting containers from YARN, takes up resources of its own that must be budgeted in. In yarn-client mode, it defaults to a 1024MB and one vcore. In yarn-cluster mode, the application master runs the driver, so it’s often useful to bolster its resources with the –driver-memory and –driver-cores properties.
Performance – Determining the number of executors:
It’s important to think about how the resources requested by Spark will fit into what YARN has available:
– yarn.nodemanager.resource.memory-mb controls the maximum sum of memory used by the containers on each node.
– yarn.nodemanager.resource.cpu-vcores controls the maximum sum of cores used by the containers on each node.

As an example, in a cluster with six nodes running NodeManagers, each equipped with 16 cores and 64GB of memory:
The NodeManager capacities, yarn.nodemanager.resource.memory-mb and yarn.nodemanager.resource.cpu-vcores, should probably be set to: 63 * 1024 = 64512 (megabytes) and 15 respectively
We must avoid allocating 100% of the resources to YARN containers because the node needs some resources to run the OS and Hadoop daemons.
In this case, we leave a gigabyte and a core for these system processes.
An executors configuration approach could be:
–num-executors 17 –executor-cores 5 –executor-memory 19G.
This config results in 3 executors per node, except for the one with the AM, which will have 2 executors.
(executor-memory was derived as (63/3 executors per node) = 21. 21 * 0.07 = 1.47. 21 – 1.47 ~ 19)
Conclusions:
- Depending on the application size (memory), using small executors (several executors per node) will perform better.
- If the executors are too tiny (with a single core and just enough memory needed to run a single task, for example) throws away the benefits that come from running multiple tasks in a single JVM.
- The application master, which is a non-executor container with the special capability of requesting containers from YARN, takes up resources of its own that must be budgeted in. In yarn-client mode, it defaults to a 1024MB and one vcore. In yarn-cluster mode, the application master runs the driver, so it’s often useful to bolster its resources with the
--driver-memoryand--driver-coresproperties.

- In yarn-cluster mode, the application master runs the driver, so it’s useful to bolster its resources with the –driver-memory and –driver-cores properties.
- Running executors with too much memory often results in excessive garbage collection delays.
References:
http://horicky.blogspot.ie/2013/12/spark-low-latency-massively-parallel.html
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
https://spark.apache.org/docs/latest/tuning.html

Reblogged this on Hernan Vivani's Blog and commented:
This is an oldie but goldie…